 Many articles have been written about content marketing in the past years, online marketers are sometimes completely obsessed about content marketing. Because of several projects I did during the past 12 months and all those people using “Content is King” whenever possible, I would like to discuss some of the factors content marketing has an impact on. These factors are not commonly considered by everyone involved in online marketing campaigns.
Many articles have been written about content marketing in the past years, online marketers are sometimes completely obsessed about content marketing. Because of several projects I did during the past 12 months and all those people using “Content is King” whenever possible, I would like to discuss some of the factors content marketing has an impact on. These factors are not commonly considered by everyone involved in online marketing campaigns.
Due to the fast-paced development of Google, where there has been more focus on the quality of content and websites by developing algorithmic filters like Panda, many websites have produced enormous amounts of textual content on their domains. A lot of websites are still targeting specific queries with unique pages instead of targeting a specific group of people. In the company of the latest updates of Google’s algorithms, where Panda is one of them, some problems start to occur. From a technical point of view, more content is not always positively influencing the organic results.
Content cannibalisation
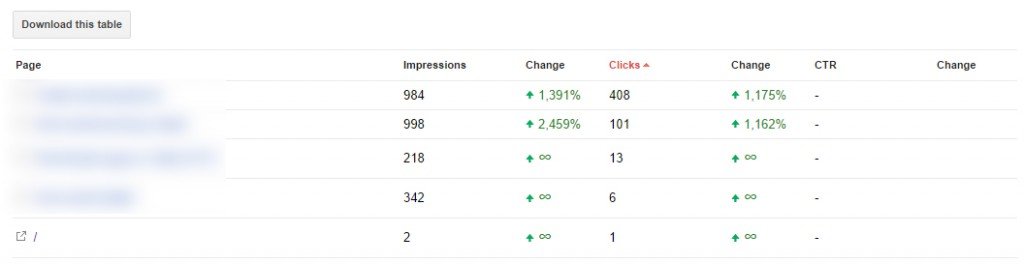
A problem that is occurring a lot, is the fact that specific pages have overlapping content. Google Webmaster Tools offers a convenient overview of the URLs that Google is showing in the search engine result pages for specific queries. The fact that multiple URLs show up for the same query can have multiple reasons: personalised and local search for example. In most cases, if more than 80% of the impressions are attributed to a single URL, there isn’t a real problem. It is a different case if Google shows 2, 3 or even 4 URLs for the same query, since Google thinks all those pages are relevant for the same query:
You can use scraping software to run through your dashboard automatically. Unfortunately web based scrapers won’t work that well since you have to login in and WMT is built with JavaScript so you need a screen based scraper. For an overview of the different kind of tools you can use for web scraping, have a look at the article Six tools for web scraping.
To start with, make sure you download all the top queries with the “Download this table” button. Open these in Excel, and add a column where you will merge these keywords into the URLs you need information scraped from. WMT is using really simple URLs to access search query specific pages. The overview page can be found at:
https://www.google.com/webmasters/tools/top-search-queries?siteUrl=http://www.notprovided.eu/&hl=en
and specific keywords can be found at:
https://www.google.com/webmasters/tools/top-search-queries?siteUrl=http://www.notprovided.eu/&hl=en#web scraping tools
You can just merge that URL with the column of keywords. The next step requires a screen scraper tool, since you have to login and you need a browser to view the pages within WMT. You can use Outwit Hub, UiPath or Visual Web Ripper which is a bit more expensive. Within this software, login to WMT to gain access within the browser. Have a look at the guides of both software packages to see how to upload a list of URLs and scrape the number of URLs shown by Google in the SERPs per query. You can easily filter this sheet for queries that have more than one URL showing up in the SERPs. Another option is to use analytics or your site search function to see what content is returning for specific queries, but that is purely from a users perspective and not that of Google’s algorithms.
The number one rule should be: make sure you have just one page per concept you want to rank for. This same report within WMT can also be used to see if Google is using the right URL most relevant to the query. It could be that a blog post about a specific topic is more relevant for a commercial intent query than a product or category page. In that case, analyse the differences in content and link value per URL and adjust your content and website accordingly.
Interpreting content quality
The quality of your content is becoming more important now Google is advancing towards a more humanized algorithm. In the light of the latest Panda update, the list of 23 questions Google published in May 2011 is still relevant: “More guidance on building high-quality sites”
Three of the questions summarize the concept of “quality content” really well:
- Are the topics driven by genuine interests of readers of the site, or does the site generate content by attempting to guess what might rank well in search engines?
- Does the article provide original content or information, original reporting, original research, or original analysis?
- Does the page provide substantial value when compared to other pages in search results?
Make sure you use this list when you are creating your content marketing strategy. Last week, Russ Jones published an article (Panda 4.1: The Devil Is in the Aggregate) in which he shared some data about the winners and losers during the latest iteration of Panda. Jones answers the 23 questions and looks for correlations between the different factors. These kind of studies need to be taken with a grain of salt since there are a lot of differences between specific query spaces.
Link value distribution
For starting websites or really large websites it is difficult to get enough quality links to all pages to have sufficient link value to compete with the top 5 websites in the search engine result pages on competitive headtail queries. The more pages your website has, the less link value an average URL will have. This is simple math, so think about the fact that adding more pages to your website can negatively influence the performance of current pages. Think about how you want the incoming link value, for which the homepage will be the biggest hub in most websites, to flow through your website and find its way to the URLs that need to be in the top of the search engines.
Crawling budget
An underestimated factor during a lot of SEO projects is the optimisation of the website and internal link structure. Based on the quality and number of links pointing to your domain, search engines reserve a proportional amount of crawling budget for every website. As is the same with link value, the more pages you will have, the less amount of crawling budget will be available per page. For other purposes, like optimizing your AdWords campaigns, it can be a good idea to add specific landing pages but keep in mind which pages also contribute to the organic channel.
To optimize both link value distribution and efficient spending of crawl budget, make use of nofollow and noindex tags in combination with exclusion via robots.txt for pages that won’t have additional value to SEO and are consuming valuable links and time.
From specific queries to concept optimisation
With the introduction of Hummingbird in combination with semantic databases like Google’s Knowledge Graph it becomes more easier to get an idea about the topic of a page without using specific elements like <title> <meta> or <h1>. Instead of using a keyword relevancy database, Google will be able to apply concept identification. This means you won’t need specific pages for [cheap iphone], [iphone specifications] and [battery iphone] anymore, but you can built one page which contains all that information. To be honest, creating thin content landing pages still works in a lot of countries and specific niches, but be aware for future manual and algorithmic actions.
Content marketing: it is not just about the content
The most important tip is simple: content is really important to get good results with SEO but look to your website as a whole when doing content marketing. During content strategy development, ask yourself: what is the effect of adding content to the website? What are the consequences of adjusting content? Google is King and that king likes simplicity. Before you know, Panda is walking around your server.
Panda image: © Dreamworks
Hello, really nice article. Is there a way to scrape keyword and corresponding pages from search console with free tool?
Thanks
Hi Sergey,
It is not needed to scrape anymore, there is a great API available for that data right now: https://developers.google.com/webmaster-tools/