During the core updates Google rolls out every year, SEOs often discuss the impact of vague concepts like EEAT, content relevancy and the number of external links. In many cases the reason of loosing visibility in search engines is simple: Google interpreted a search query different, causing a shift in conceived user intent. Target pages do not align with the intended user intent, hence dropping out of the top 5.
All scripts used can be found on https://colab.research.google.com/drive/1dL7tHt-9xJwiQ8YSnEmTA7z8kLHKNpvw?usp=sharing
User intent is often simplified: what kind of content types show up for a specific set of user intents. Traditionally we have been categorizing keywords in four different types: (content from GPT4; Prompt: What are search intents?)
There are typically four primary categories of search intent:
Informational Intent: The user is looking for more information on a particular topic, question, or idea. Examples of such queries might be “how does photosynthesis work?” or “history of the Eiffel Tower.”
Navigational Intent: The user knows which site they want to visit and is using the search engine to get there. For instance, typing “Facebook login” or “OpenAI website” indicates that the user is likely trying to navigate to those specific sites.
Transactional Intent: The user is ready to buy or is looking to perform some type of web-based activity, like shopping. Searches like “buy iPhone 12” or “best prices for running shoes” typically fall under this category.
Commercial Investigation: The user is looking to make a purchase soon but wants to compare and review products before making a final decision. Examples might include “best DSLR cameras 2021” or “top-rated smartphones.”
Looking to some random search result pages across languages and regions shows we need a much more specific set of intents. Using Large Language Models (LLMs) to predict search intents is possible, but it is just guessing. Lots of relevant context is missing which results in non actionable output. An example based on an input of four different keywords:
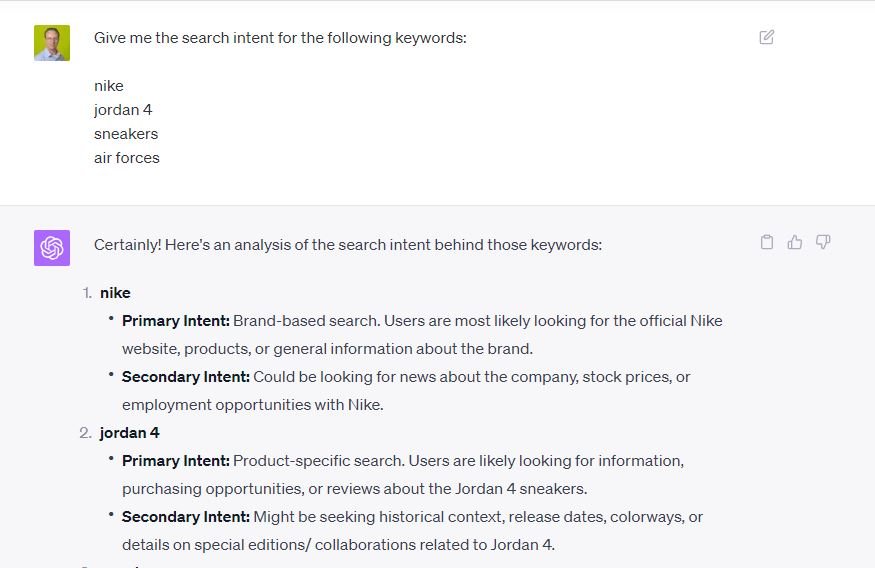
If you try some other prompts, like “What is the search intent for the keyword “rank tracking software”? the model actually acknowledges it is guessing. Look at all those words pointing to the uncertainty:

But we are a bunch of lucky people: according to GPT4, search engines have become much better in determining what their users expect. Prompt: “What are search intents?” gives us a nice hint were to start looking when we need a systematical approach to search intent.

Lets agree that Google as a platform is much better in this than 3rd party tools that have less user based metrics and datasets. Even if Google’s algorithms are not doing a good job, we still want to create the highest chance of ranking in the top spots. So let’s go back to the actual search engine result pages and use that as a starting point to create a better tailored system:
- Create a database with keywords and ranking URLs
- Collect body content and classify URLs
- Identify best ranking content type
- Create follow up tasks
- (Bi-) Weekly & Monthly repetition
Create database with keywords and ranking URLs
One thing I can be very clear about, do not use browse plugins like VoxScript or Keymate.ai in combination with a GPT model to scrape Google search engine result pages (SERPs). That is a painfully slow and expensive process. It may work for one-time checks but goes wrong for repetitive tasks. There are dedicated API’s from standalone services available that can check SERPs in a low cost and faster setup. They take care of randomized IP’s and browser fingerprints and have a focused approach on getting the data for you.
Generally speaking their performance is fine for small batches like a few thousands keywords. Just to name a few to get an idea for the costs involved:
| Provider | Avg. Costs |
| Valueserp.com | $0,50 / 1000 |
| Dataforseo.com | $0,60 / 1000 |
| Oxylabs.io | $2,80 / 1000 |
| Serpstack.com | $6,00 / 1000 |
| Serpapi.com | $8,33 / 1000 |
The first step is to create a database containing the top 30 URLs ranking for the set of relevant keywords you or your client wants to rank for. For the sake of simplicity of the examples, we just want to focus on the organic ranking URLs and we do not include SERP elements like knowledge graph blocks, featured snippets, Google Ads etcetera. It is recommended for your final process to include feature snippets since they show a (sub)intent related to the informational intent.
Using the SERP API from Valueserp.com we can use the following script to get the top 30 URLs per keyword:
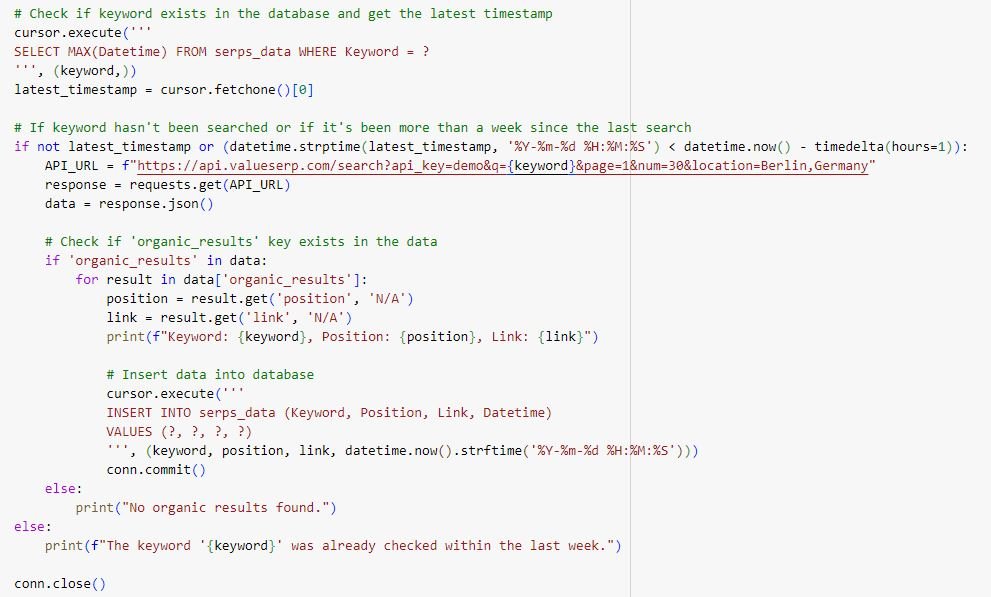
Once you have the SERP data collected, I advice to recheck rankings every two weeks. Relevant shifts are only visible if you zoom out for longer periods and usually happen around core updates. You can always manually update the dataset if you know a core algorithm update has been rolled out and rankings have shifted considerably. The example below shows how relatively stable the top10 rankings are for a 6 month period until the core update hits the SERPs:
I have calculated volatility numbers for different timeframes based on historical datapoints to check the most relevant period to use. It turns out checking the ranking URLs every 2 weeks is fine. Yes, you will miss the occasional newcomer but 93% of the relevant changes are visible when using a 2 week period.
Collecting body content
Since we now have a nice dataset with keyword and ranking URLs, we can start looking to the content on those URLs. For the examples below I will use a manual input of URLs but you can easily connect the database from above. Ask GPT4 to update the Python script for you if you are lazy 🙂
The quickest way is to use Python with BeautifulSoup to request a URL, scrape the body content and go to the next URL. Unfortunately that doesn’t work as well as it used to do due to many CDN solutions have built-in scraper / bots detection algorithms running. To circumvent that partly, it is important to fire up a real browser and mimic real users. The easiest solution is Selenium which also enables client side JS rendering. Since you can set all browser variables and combine it with selenium-stealth or undetected_chromedriver to have higher success rates. In 90-95% of the URL requests this prevents getting a “are you a robot, dude?” or “Forbidden” response.

For websites that have set up higher level of protection (usually well ranking websites have better anti bot measures in place unfortunately) it is recommended to pay a little extra for dedicated services like like ZenRows or WebScraping API for about $50 / month for 80-100K URL requests. If you zoom in to the top 5 ranking pages to determine most successful content types, you need to be sure you have actually collected the content of those 5 URLs.
In the colab you can find a basic script. This script can be extended with an additional loop to use the external APIs to request URLs that return a blocked message initially.
To make things more effective, you should also built in a check to see if a specific URL has already been scraped for another keyword. This prevents scraping individual URLs multiple times.
Additional notes for collecting body content
In live environments I have built in some output cleaning like removing comment sections and preventing inclusion of content from header, nav and footer elements. Some default CMS have “skip to main content” links and a table of contents, remove those.
Be aware that some of the models that you can use for classifying have an input limit of 4096 tokens and having the cleaned up content as input performs better with the classifying process.
Classify content into content types
Most LLM models are not specifically trained for classifying a piece of content based on a set of previous unknown rules (we come up with the input of a number of content types). So you can try inputting a prompt like “Give me the search intent for the following keywords: nike, Jordan 4, sneakers, air forces’ but the results are not something you should depend on in future analysis because it is missing relevant content.
Since you need to process lots of content pieces, latency can be of importance. A nice monitoring dashboard for current latency averages for popular LLMs can be found at https://gptforwork.com/tools/openai-api-and-other-llm-apis-response-time-tracker Classifying 15000 URLs / content pieces with a latency of 10s per request means a total processing time of 42 hours.
Hosting your own LLM
Latency was my biggest annoyance during building my first setup, I started using locally hosted LLMs. You can easily set up GPT4ALL on your local PC. It can be loaded up with a few well known models out of the box. The greatest thing is you can easily switch models or use your own model. Not every existing model is suited for classifying: on https://github.com/Troyanovsky/Local-LLM-Comparison-Colab-UI you can find an overview and scores given for 68 different models. Models where tested for specific tasks like translating, summarizing, answering, rewriting, sentiment analysis etcetera.
Finetuning models
Models available are not specifically trained and suited for classifying content into a unique set of content types like we SEOs need. To help them out, we can finetune the current models without needing to fully train and built out a full model. https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset shows how to prepare your own dataset (manually classified content dataset in this case) and how to finetune an existing model. OpenAI recommends 50-100 training examples, but I have done test with 500-1000 examples to finetune gpt-3.5-turbo to get to a usable model for my setup:
| URL | GPT 4 | Finetuned GPT 3.5T |
| https://startupbonsai.com/rank-tracking-tools/ | Comparative lists | Comparative lists |
| https://bloggingwizard.com/rank-tracking-tools/ | Product pages | Comparative lists |
| https://diggitymarketing.com/best-rank-tracker-tool/ | Guides | Comparative lists |
| https://www.searchenginejournal.com/seo-tools/rank-tracking-tools/ | Guides | Guides |
| https://searchengineland.com/keyword-rank-tracking-software-6-tools-compared-387503 | Comparative lists | Comparative lists |
| https://nealschaffer.com/best-rank-tracker-tool/ | Guides | Guides |
| https://www.link-assistant.com/rank-tracker/ | Product pages | Commercial |
| https://www.g2.com/software/rank-tracking | Commercial | Comparative lists |
| https://www.ranktracker.com/ | Product pages | Product pages |
| https://www.adamenfroy.com/rank-tracking-software | Reviews | Comparative lists |
Speeding up processes
All the above scripts run in a linear setup. They process one SERP, one URL, one piece of content and then process the output. Once the output has been processed, it goes to the next SERP, URL etcetera. Going one by one is not most time effective, so have a look at possibilities for running tasks in parallel. A good start is reading up on the differences (and limitations) of Multithreading and Multiprocessing in Python
Create follow up tasks
A rich database with classified content is what we now have at our disposal. Now we can determine the best ranking content type per keyword. This is the most simple task: check for the most common content type amongst the top 5, excluding the target URL of your or your client’s website.
If there is no clear winner (like two A types, two B types and one C type) or there are unique content types in the top 5, extend your selection to the top 10. If that doesn’t give a clear winner, extend to top 20.
Upfront I already have clustered a set of relevant keywords to target one specific URL. We can compare the content type of the current or proposed target URL with the content type that has the highest chances for ranking high.
If they align, you have to look to other SEO activities to improve rankings. External links, optimizing the existing content, internal linking etcetera. If content type does not align, you can go on with creating a content briefing for your text writers.

One example to show you shouldn’t use LLMs to write content, that’s all I want to say about it in this article. (Oh yes, I know you can use LLMs for specific text generation processes, but not for this). Out of the 5 tools listed in the blog, 3 of them didn’t exist. If you want to work with factual information, make sure you either include the facts in your prompt or ask a human being.
Bi Weekly & Monthly repetition
As said above, a 2 week period often catches most ranking changes relevant to intent changes. Content changes on the actual ranking website are a bit different between niches and the type of content ranking. You may want to built in a check for last-modified headers or tags to prevent unnecessary scraping activities and make the whole system run faster.
Summarized, I run this in the following configuration:
- (Bi-) Weekly repetition:
- Request top 30 rankings, check for new URLs
- Calculate best ranking URLs over the past 2 weeks
- Download content & classify newly found URLs
- Check if the top 5 and your project target URL has changed
- If yes, adjust advice for content team
- Request top 30 rankings, check for new URLs
- Monthly repetition
- Request top 30 rankings
- Download and classify all URLs
- Calculate best ranking URLs over the past 2 weeks
- Classify content for best ranking URL of your project, if availabe
- Adjust content requirements and briefs if necessary
Evaluation of the system
For my first setup I spent 22 hours for a 5000 keyword set. It turns out to save me lots of time (vs manual checks and briefs) which equals less costs for the client or more time available for other analysis. The great thing about this setup is that the data you collect is very valuable.
There is lots of tweaking and additions possible in the system. Since you have the content of the best ranking websites available, you can extract all entities, topics, keywords, etcetera in there and see if your target URL also has these covered. Combine the dataset with external link data and you can push for automated link building briefs (eg. This glossary page requires at least 5 more external backlinks with a minimum requirement of X, Y, Z.)
Looking to general trends within a industry, like blogs starting to rank instead of e-commerce category pages, may justify a change in SEO strategy and requires a change in internal UX and taxonomy structure. Those are decisions where I think the value of using AI stops and our human brains need to take over.
All scripts used can be found on https://colab.research.google.com/drive/1dL7tHt-9xJwiQ8YSnEmTA7z8kLHKNpvw?usp=sharing