
Many of you will have notices the search engine result pages are currently containing more elements compared to a few years back. Not only 10 blue links, accompanied with 3 to 10 AdWords advertisements but for many queries we are getting additional regarding the query. These additional cards are a result of Google’s Knowledge Graph. Not familiar with the concept Knowledge graph? Just ask Google: “The Knowledge Graph is a knowledge base used by Google to enhance its search engine’s results with semantic-search information gathered from a wide variety of sources.”
Sounds complicated, but is isn’t. If you ask for information, Google will try to answer your informational need directly within the result pages. The main reason why this impactful change within the search engines (Bing, Yandex and Baidu also have similar systems in place) is taken place so rapidly, is the changing human and so the searching behaviour.
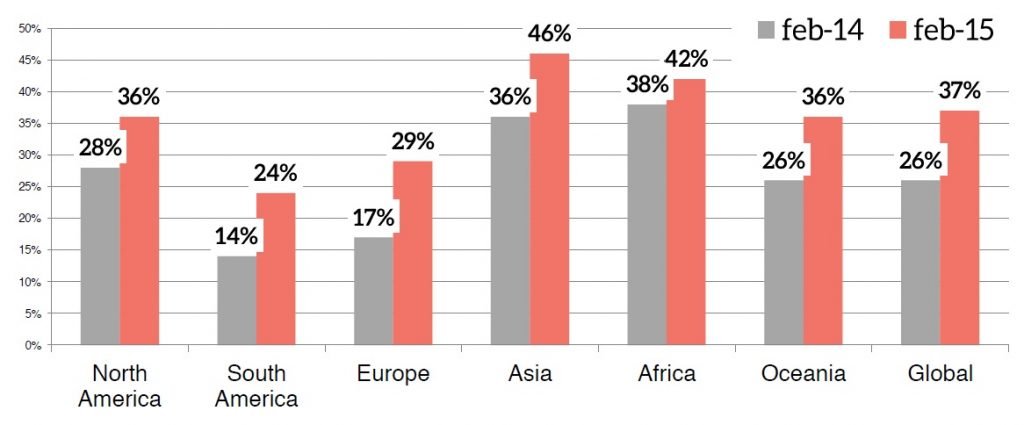
Source: Statcounter
Mobile and tablet devices are responsible for a huge part of the pageviews made on the world wide web. For specific niches, mobile search is over 50% already. Since a few weeks you can actually find the ratio between mobile / desktop queries within the Google keyword planner. Click on the “Search volume Trends” button in the left top corner so get a graph showing you the ratios per query space or if you input individual keywords, for specific queries. Mobile and tablet devices have limited screen sizes, so limited space to show information. To make it as easy as possible, Google is providing the so called Knowledge Cards in their result pages. These are compatible with all kinds of devices, even ready for future developments like everything in the category wearables. Instead of browsing through websites, you will get easy to consume answers on your queries.
Eric Schmidt: “In each case we’re trying to get you direct answers to your queries because it’s quicker and less hassle than the ten blue links Google used to show. This is especially important on mobile where screens are smaller and typing is harder.”
Voice search is one of the major UX improvements Google made. Have a look at the presentation of Behshad Behzadi, Director of Conversational Search and his keynote session during SMX Munich “Did Captain Kirk use Google? The Future of Search!”. Google’s mission is clear, gather all the information possible and make that information universally accessible. Sounds like a clear job, but unfortunately not the most easy job as you can imagine. Research is needed, but it is remarkable that most of the research that is being done by Google’s researchers is in the field of Artificial Intelligence and Machine Learning. You would expect fields like data mining, NLP and IR to have more priority but Google is really looking to the future.
The main source of information Google has been using during the past years is Freebase. It was purchased from Metaweb in 2010 and was used by Google to built their first useful Knowledge Graph. The information available via Freebase, could be directly accessed via Google. Until now it seems there is no or almost no verification system in place. Currently Google shows I’m 67 years old, but it also has access to a lot of my social profiles around the web and they all state something different. Shouldn’t be so difficult right? Think about the scale Google needs to solve and process certain informational needs. The other factor in play, is the risk of using human annotated data. Like Einstein said, humans are infinitely stupid. And then there are SEOs like me who try to influence everything that comes up in search engine result pages. After a few years of testing, Google needs to move on. Freebase is basically a structured data version of Wikipedia, and researchers from Google noticed in their paper about the Knowledge Vault: “Wikipedia growth has essentially plateaued, hence unsolicited contributions from human volunteers may yield a limited amount of knowledge”
How to collect and store “facts”
To understand the challenges Google is facing, you need to understand how they collect and store information. Information is stored in Triples. Triples represent facts in the form of relationships, in the form of a subject, a predicate and a object. Subject and object are entities and the predicate is the type of a relation.

Wikipedia is not sufficient anymore, so Freebase will close down. But Freebase was also somewhat limited in terms of predicates. It only contained 200 attributes for the class Country but you can come up with thousands of predicates relevant for the Country entities of course. In total Freebase contains 35.000 predicates, as you can see in the table, Google started out by copying those predicates directly into their first version of the Knowledge Graph. Hence you get direct results when you are changing information in the Freebase.com dataset.
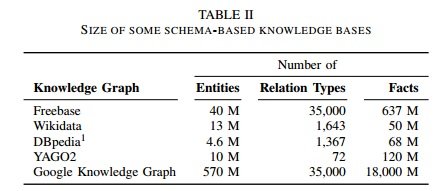
To be able to answer many more questions, Google needs to understand more relationships to extract more facts. One of the research papers by Google (Biperpedia: an ontology for Search Applications) describes a system that is able to identify four times as many attributes for the class country compared to the current Freebase dataset. It combines different data streams, in this case Freebase and the web corpus. Based on these streams of data Google is able to extract more attributes and understand many more relationships. As you can imagine, Freebase is annotated via a semi automated system, but it never includes any misspellings or synonyms but Biperpedia is able to deal with it really well.

Understanding relationships is important, but without any data there is nothing to understand. The Knowledge Vault paper from last year, gives some insight into how Google is able to extract data from the web. The system described in the publication basically uses four distinct ways of extraction data:
- Text based: using natural language processing, combined with entity recognition makes it possible to extract triples out of plain text. To be sure verification takes place against the Freebase dataset. Parents are often married, so if a text states mum and dad are married and Freebase shows that they are both parents from one sibling also mentioned in the text, the system is able to identify the relationship.
- The HTML DOM: the Document Object Model is a convention for representing objects within HTML. By using the DOM, the system can use forms, to get into deep web sources. One of the applicable systems is using the internal search engines within a specific website to find and extract additional information.
- HTML Tables: the relationship within a table can be defined by using the column headers. If not clear, the system looks to the entities within the columns and uses Freebase to match and map specific relationships between the entities.
- Human annotated data: the system uses Schema.org annotations to detect events, products and people. In this specific paper they just use 14 predicates related to people.
As you can see, the Freebase dataset is use to verify and making extraction of entities more reliable or even possible. The Knowledge Vault concept is based on probability scores. The more documents contain specific triples, the more likely a triple is true. The threshold for this specific system seems to be around 20-25 documents. But this also works the other way around, for false triples. Interesting paragraph is the one in which they discuss “duplicate” triples. If a websites contains duplicate content, or mentions a specific triple multiple times, it is being considered as just one source. So you can’t trick their systems into getting the wrong “facts” into their Knowledge Vault.
Back to the data extraction itself, Google has developed numerous systems to extract data from web tables. One of the results of their research can actually be used by you and me: Google Tables (experimental). The paper “Applying WebTables in Practice” shares some insights in how Google finds, extract and processes web tables. Four factors are in play according to that specific paper:
- Surrounding content: optimise the surrounding content with relevant captions and texts.
- Table headings: use <th> table headings to add labels to specific columns
- Attributes: add relevant attributes to your table headings focusing on the queries used
- Table contents: only add useful content to the table. Boilerplate content is filtered out.
Not rocket science, but good to consider and become familiar with the factors that are determining how you can make it more easy for Google to understand your content. Data extraction can be done on a large scale but one of the main issues of Google right now is verification. Since the whole concept of the Knowledge Graph is based on probability scores, every “fact” is a calculated guess. This makes it interesting, as can be read in the paper: “Inference is an iterative process, since we believe a source is accurate if its facts are correct, and we believe the facts are correct if they are extracted from an accurate source”. Extraction and verification are causing more false triples compared to the amount of false information online. So the key to getting the right results in the search engine result pages is verification.
Knowledge verification
There are a few papers describing triple verification methods but this basically is really simple;
- Use anchor texts: these can be used to extract objects, subjects and predicates quite easily. People tend to link with descriptive anchors anyway. This would explain the reason a crappy answer card is showing up for the “WordPress designer” query in Google.com
- Use a search engine: Google has the luxury position of having a search engine directly available. Check the results which return already when searching for specific entities, check the web corpus, use natural language processing to verify.
- Ask humans: built in user feedback in the process. Google already built in a feedback form for most of direct answer cards right Not enough user data? Just send a questionnaire to a panel. To get some systems running based on initial data, they use inhouse teams to label sets of data.
For data they really need to be sure about, for example medical related data (One of 20 of the queries are health related in the US) they work together with respected partners like the Mayo Clinic and a number of government agencies like the National Institutes of Health. All their partners can be found at the following page “Medical searches on Google”. A lot of chatter has been around Google showing complete lyrics, similar to Bing. Both search engine work together with companies selling licensed versions of the lyrics so Google is able to monetize it via Google Play.
To summarize the whole process, I made the following illustration:

An interesting example I found when searching for tips on account creation with specific social platforms. Google is not specifically showing their own websites first. Queries related to YouTube actually generated an answer card based on the Sproutsocial.com website. What is even more interesting, is that Google included a Action within the knowledge card. This is something we should really monitor in the upcoming months, since I expect Google will push the possibility of adding specific actions by adding structured data markup to your websites, e-mails or other types of content.
Since Google is developing so rapidly, testing is important. A funny test I set up together with David Iwanow was checking the delay between changing a picture used in my personal Knowledge Card and the moment when Google would update it. Google was showing the picture included in the article http://lostpr.es/interview/jan-willem-bobbink/ and David changed it to an angry clown. Unfortunately Google has facial recognition in place, the angry clown never showed up when searching for my name. Currently, a few e-commerce related queries are showing answer cards, which are really close to advertisements. Check this example, credits to Cyrus Shepard:
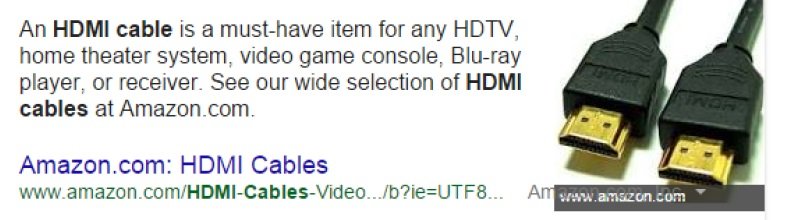
The HDMI cable example is interesting because Google doesn’t see it as a commercially focused query but as a topic, hence the related topics below the answer. People on Twitter were discussing about the number of references, caused by the huge number of duplicate content domains. Like I showed earlier, duplicate references will be filtered out when determining the probability of a triple. A similar one showed up for “peanut butter maker” but I expect that Hummingbird kicked in, re wrote the query and answers a real question: “How to make peanut butter”. The combination of Hummingbird and querying specific questions is interesting. Try these three queries in Google US for example:
- The fastest car in the world
- Fastest cars in the world
- The fastest cars in the world
Subtle differences but the results are completely different so Google is really getting into the understanding of queries.
Branded Knowledge Card optimisation
Next to the answer cards, there are brand cards being shown on the right side of the SERPs. There are a number of things you can (try to) influence. Most of the factual data is taken from Wikipedia, directly via Freebase. Wikipedia and in the structured data form Wikidata will still be a starting point for Google to help them with extraction and verification. They will still need human annotated data to train there models. I’m not going into detail about Wikipedia optimisation strategies but during the years I’ve been mainly successful with editing when I’m using a lot (really a lot) sources to back up my edits or contributions to specific pages or creating new pages.
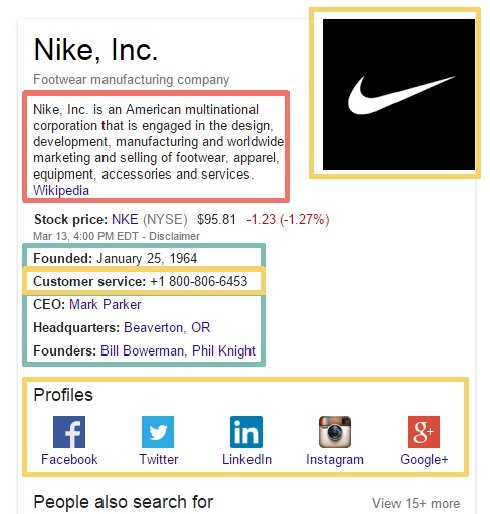
Since a few months Google is allowing you to help identifying the best information about your brand by adding structured data code, in the form of JSON-LD to your website. By doing this, you can help Google finding the correct logo, contact details and the correct links to the main social profiles. Since they prefer JSON-LD to do this, just add the specific JavaScript codes to your homepage and Google will pick it up immediately. Be aware Google uses this as a tip, so it doesn’t mean they definitely will add the changes to their knowledge cards, it’s merely a directive for Google. If your logo doesn’t match with the thousands other logo’s recognized for your brand, Google won’t change it. Using a phone number specifically for the knowledge cards won’t work, Google will need to find that number on other pages too.
Optimisation possibilities
Currently, Google returns Knowledge Cards for 19% of the questions that are beind asked. Stonetemple did an impressive case study using a dataset of 850.000 questions: Google Provides Rich Answer Results to 19% of Queries Used in Our Test For the US and UK the number of knowledge cards showing up is much higher compared to non-English indices, simply because of the fact that Google is not as good in understanding other languages yet. To answer questions, you need to understand them. Lucky for me, I have a few international clients, also present in the English markets and I have been doing a few tests on why specific pages are being shown as answer cards. A few factors to keep in mind:
- <title> element: Contains the main subject of the required answer
- <h1> element: Contains the main subject of the required answer
- Page content: Within the content, the question is answered in a single sentence
People often talk about authority when discussing SEO but that is still really difficult to determine. What makes a page authorative for a specific query? 10 webshops, all selling the same product, what is difference for the user if they just want to buy that specific product? Price, shipping costs, customer service etcetera. None of that is measurable by Google. So logically, I did found any signs of “authority” being important to start showing up with answer cards. What is not logical, is the fact (pun intended) that different search engine indices show up different facts. In the UK the Volvo S60 is the safest car, in the US it is a SUV. Eh, get your facts straight Google 🙂
My advice to every SEO, start testing right now. Not many people have tried to adjust content that suits specific answers yet. Based on a small dataset of about 400 queries, I have been able to get some nice results for clients. In almost 95% of the cases the client’s traffic increased. Distinction should be made on the version and contents of the answer that shows up:
- Cards without a “more info” link: Results varied between -3% and +11% depending on previous position in the SERPs
- Answers that included a offer: These were performing the best, increases between 6 and 14%
- Lists as answers: Less than expected, probably because of quality of the answer: results between -5% and +6% traffic.
- Partially answered questions: Depending on the topic, complicated topics tend to get more clicks. Average results between -2% and 16% increase
As you can see, in some cases traffic dropped. Users getting the answer directly or the answer is not what users are looking for will make them click any of the ten blue links below it. There are still enough queries without any answer card showing up yet so get starting with optimising right away!
Comments
3 responses to “Optimising Google’s Knowledge Graph – #SMX Munich”