Category: Technical SEO
-

Search Seekers – How to keep growing organic traffic for already well ranking websites
During Searchseekers.de I shared 10 #SEO tactics I use for websites that already rank well but have plenty of opportunities to grow. Any questions? Feel free to comment or DM! 1. Are you actually properly indexed?2. Pruning your non valuable content3. Examine the index strategies4. Using Internal link value effectively5. Crawl based optimization6. Scaling content: covering all search intents7. Focus on other Google based channels8. Using…
-
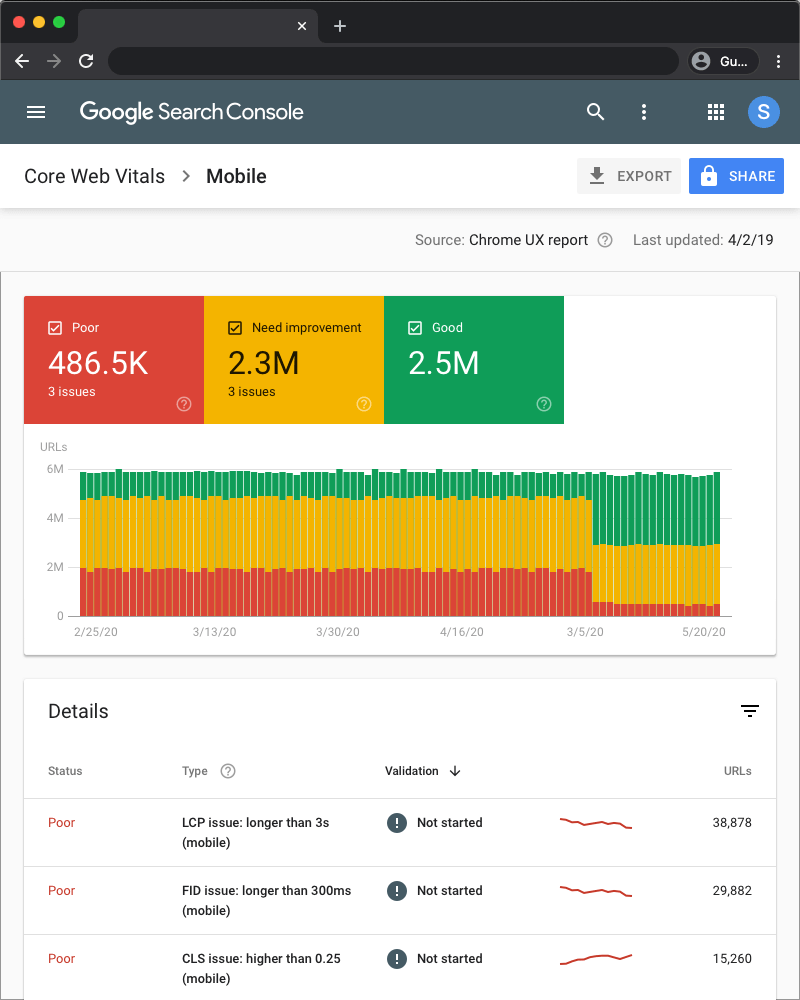
Get page level Core Web Vital data from competitors in Search Console
Let’s say you have a lot of crawl budget assigned to your domain and you want to use it to benchmark your own Core Web Vital metrics against your direct competitors. Using Chrome UX report APIs is OKish for domain level metrics but you obviously want more data.
-
What I learned about SEO from using the 10 most used JS frameworks #brightonseo
JavaScript will define and impact the future of most SEO consultants. A big chunk of websites has, is or will move over to a JS framework driven platform. Stack Overflow published an extensive study about the data gathered from an enquiry amongst more than 100.000 professional programmers’ most used Programming, Scripting and Markup languages: read…