JavaScript will define and impact the future of most SEO consultants. A big chunk of websites has, is or will move over to a JS framework driven platform. Stack Overflow published an extensive study about the data gathered from an enquiry amongst more than 100.000 professional programmers’ most used Programming, Scripting and Markup languages: read more at Most Popular Technologies The outcome is quite clear, it’s all about JavaScript today:
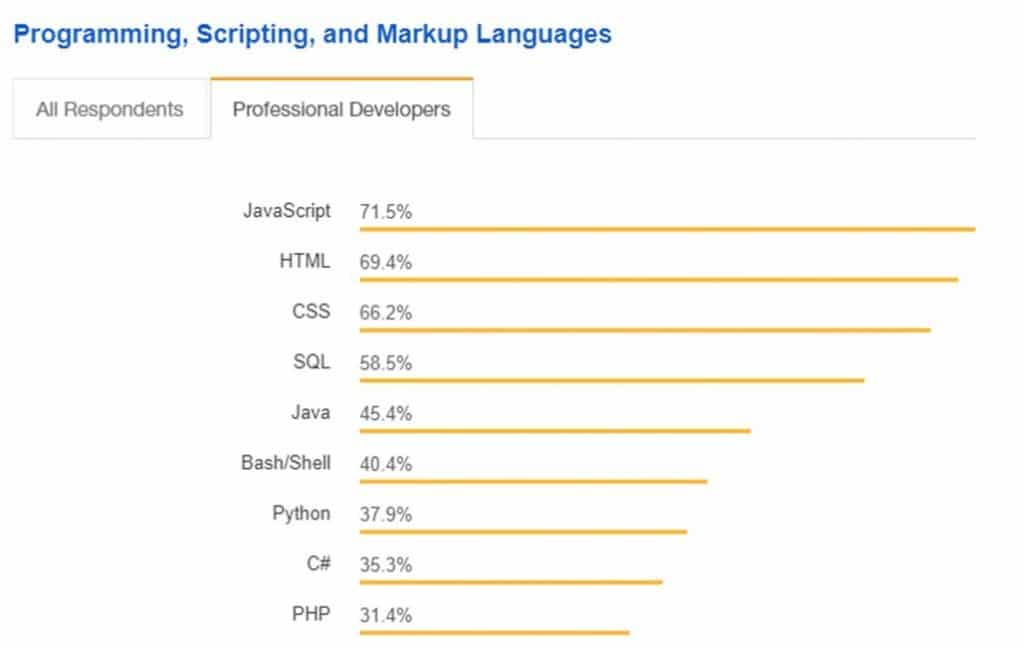
But JavaScript and search engines are a tricky combination. It turns out there is a fine line between successful and disastrous implementations. Below I will share 10 tips to prevent SEO disasters to happen with your own or your clients sites.
1. Always go for Server Side Rendering (SSR)
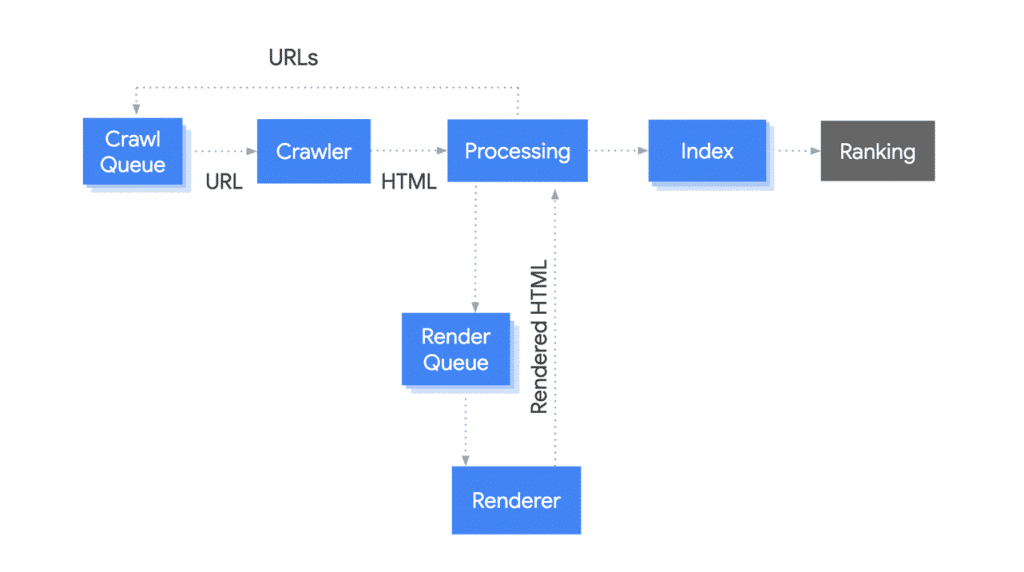
As Google shared earlier this year during Google I/O the pipeline for crawling, indexing and rendering is somewhat different from the original pipeline. Check out https://web.dev/javascript-and-google-search-io-2019 for more context but the diagram below is clear enough to start with: there is a separate track, also known as the second wave, where the rendering of JavaScript takes place. To make sure Google has URLs to be processed and returned to the crawl queue, the initial HTML response needs to include all relevant HTML elements for SEO. This means at least the basic page elements that show up in SERPs and links. It’s always about links right? 🙂
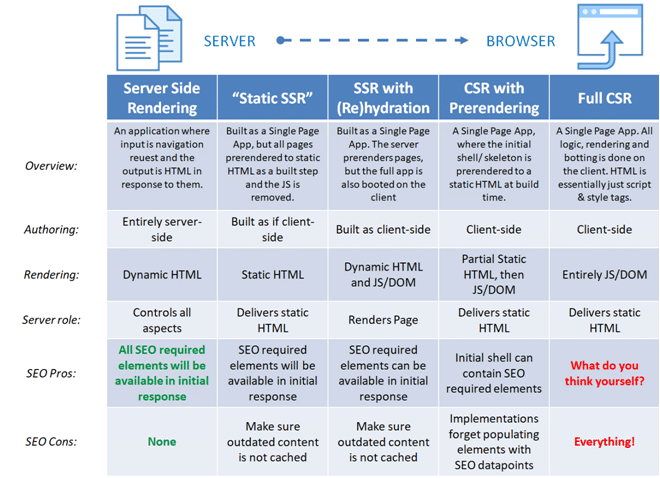
Google showed numerous setups in their article about rendering on the web but forget to include the SEO perspective. That made me publish an alternative table: read more at https://www.notprovided.eu/rendering-on-the-web-the-seo-version/
Server Side Rendering (SSR) is just the safest way to go. There are cons, but for SEO you just don’t want to take a risk Google sees anything else then a fully SEO optimized page in the initial crawl. Don’t forget that the most advanced search engine, Google, can’t handle it well. How about all the other search engines like Baidu, Naver, Bing etcetera?
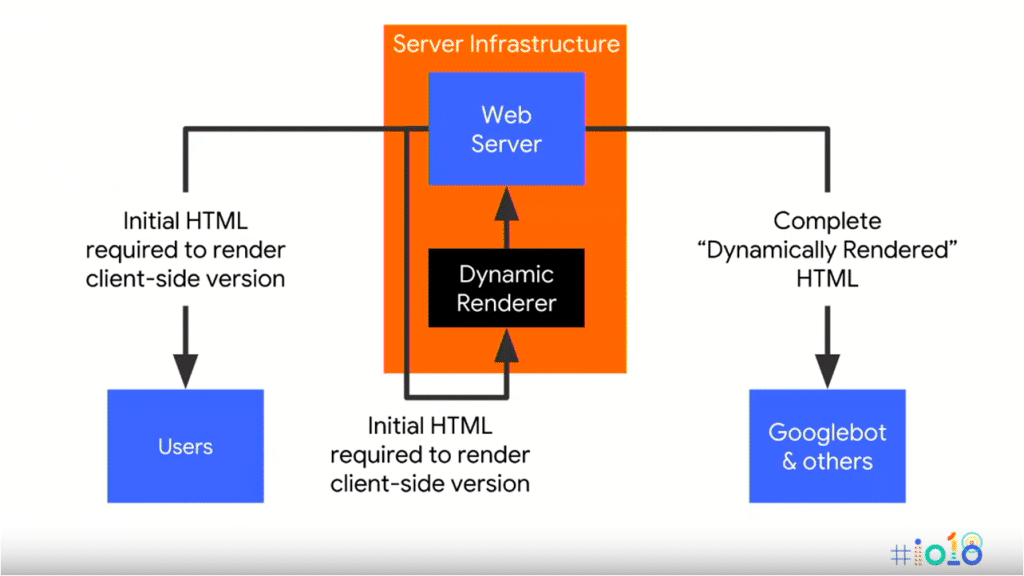
Since Google openly admits there are some challenges ahead, they have been sharing setups of dynamic rendering. Pick the best suitable scenario for a specific group of users (low CPU power mobile phone users for example) or bots. An example setup could be the following where you make use of the client side rendering setup for most users (not for old browsers, non JS users, slow mobile cell phones etcetera) and sent search engine bots or social media crawlers the fully static rendered HTML version.
Whatever Google tells us, read Render Budget, or: How I Stopped Worrying and and Learned to Render Server-Side by a former Google Engineer.
2. Tools for checking what search engines do and don’t see
Since most platforms capture user agents for dynamic rendering setups, changing it directly into Chrome is the first thing I always do. Is this 100% proof? No, some setups also match on IPs. But I would target the SSR as broad as possible, also think about social media crawlers wanting to capture OpenGraph tags for example. Targeting a combination of IPs and User Agents will not cover enough. Better cover too much requests and spend some more money on sufficient servers pushing out rendered HTML then missing out on specific platforms possibilities.
Next thing you need to check is if users, bots and other requests get the same elements of content and directives back. I’ve seen example where Googlebot got different titles, H1 headings and content blocks back compared to what the users got to see. A nice Chrome plugin is View Rendered Source that compares the fetched and rendered differences directly.
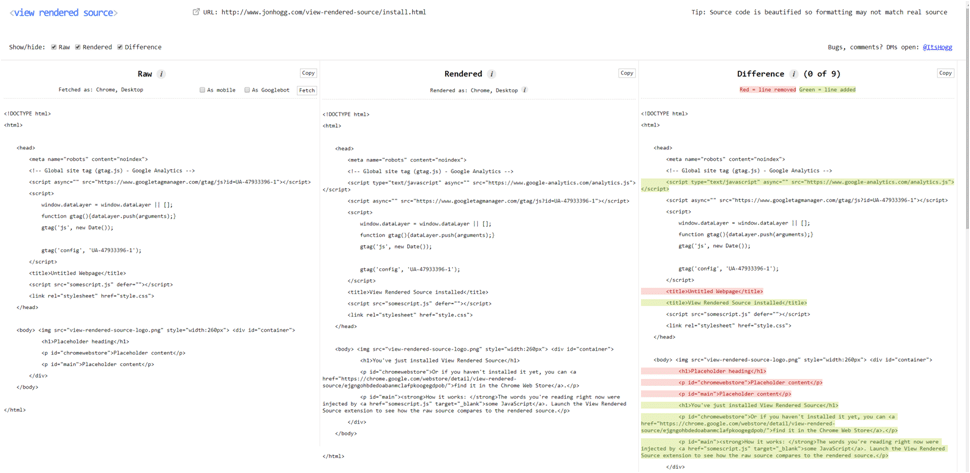
If you have access to a domain in Google Search Console, of course use the inspection tool. It now also uses an evergreen Googlebot version (like all other Google Search tools) so it represents what Google will actually see during crawling. Check the HTML and screenshots to be sure every important element is covered and is filled with the correct information.
Non-owned URLs that you want to check? Use the Rich Result Tester https://search.google.com/test/rich-results which also shows the rendered HTML version and you can check for Mobile and Desktop versions separately to double check if there are no differences.
3. The minimal requirement for initial HTML response
It is a simple list of search engine optimization basics, but important for SEO results:
- Title and meta tags
- Directives like indexing and crawling directives, canonical references and hreflangs annotations.
- All textual content, including a semantically structure set of Hx-headings
- Structured data markup
Lazy loading: surely a best practice in modern performance optimization but it turns out that for things like mobile SERP thumbnails and Google Discover Feed, Googlebot likes to have a noscript version. Make sure that Google can find a clean <img src=””> link without the need of any JavaScript.
4. Data persistence risks
Googlebot is crawling with a headless browser, not passing anything to the next, sucessive URL request. So don’t make use of cookies, local storage or session data to fill in any important SEO elements. I’ve seen examples where products were personalized within category pages and that product links were only loaded based on a specific cookie. Don’t do that or accept a ranking loss.
5. Unit test SSR
Whatever developers tell you, things can break. Things can go offline due to network failures. It could be due to new release or just some unknown bug that gets introduced while working on completely different things. Below an example of a site were the SSR was broken (just after last year’s #BrightonSEO) causing two weeks of trouble internally.
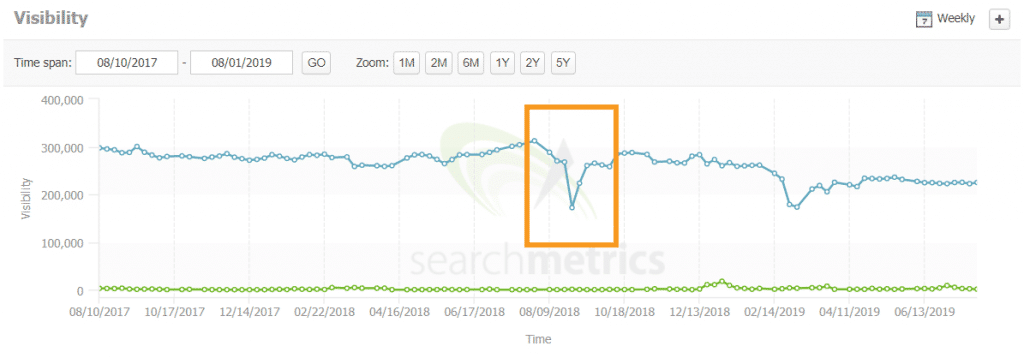
Make sure you setup unit testing for server side rendering. Testing setups for the most used JavaScript frameworks:
- Angular & React testing: https://jestjs.io/
- Vue testing https://github.com/vuejs/vue-test-utils
6. Third party rendering – Setup monitoring
Also third party rendering like prerender.io is not flawless, those can break too. If Amazon crashes their infrastructure, most third parties you’ll use will be offline. Use third party (haha!) tools like ContentKing, Little Warden or PageModified. Do consider where they host their services 🙂
Another tactic you can apply to be sure Google doesn’t index empty pages is to start serving a 503 header, load the page and send a signal back to the server once content is loaded and update header status. This is quite tricky and you need to really tune this to not ruin your rankings completely. It is more of a band-aid for unfinished setups.
7. Performance: reduce JS
Even if every element relevant for SEO is available in the initial HTML response, I have had clients losing traffic due to performance getting worse for both users and search engine bots. First of all, think of real users’ experiences. Google Chrome UX reports are a great way of monitoring the actual performance. And Google can freely use that data to feed it to their monstrous algorithms haha!

Most effective tip is using tree-shaking to simply reduce the amount of JavaScript bytes that needs to be loaded. Making your scripts more clean can also speed up processing which helps a lot with older, slower CPUs. Specifically for older mobile phones this can help speeding up user experiences.
8. Can Google load all JS scripts?
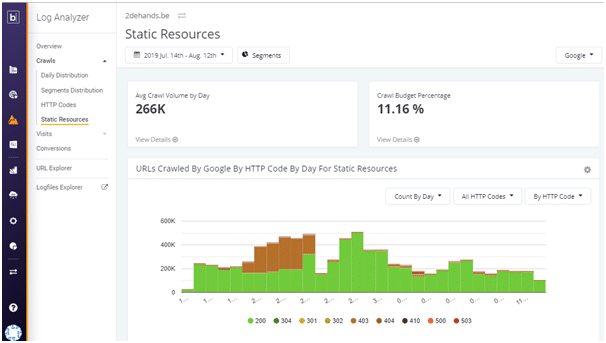
Make sure you monitor and analyze log files to see if any static JS files are generating any errors. Botify is perfect for this with their separate section monitoring static file responses. The brown 404 trends clearly show an issue with files not being accessible at the moment Google required them.
9. Prevent analytics views triggered during pre rendering
Make sure you don’t send pageviews into your analytics when pre rendering. Easy way is just blocking all request to the tracking pixel domain. As simple as it can get. Noticed an uplift in traffic? Check your SSR first before reporting massive traffic gains.
10. Some broader SSR risks
Cloaking in the eyes of search engines: they still don’t like it and make sure you don’t accidently cloak. In the case of server side rendering this could mean showing users different content compared to search engines.
Caching rendered pages can be cost effective but think about the effects on the datapoints sent to Google: you don’t want outdated structured data like product markup to be outdated.
Check the differences between Mobile and Desktop Googlebots, a tool like SEO Radar can help you quickly identify differences between the two user agents.
Comments
7 responses to “What I learned about SEO from using the 10 most used JS frameworks #brightonseo”