Many discussions have been taking place about the differences between crawling, indexing and caching. The way search engine robots are behaving can be controlled in many ways. Due to all the different possibilities, I often have discussions and have to clarify my point of view over and over again. So to be sure everyone is clear about the way you can control the crawling and indexing behaviour of the major search engines (Google, Bing, Yandex and Baidu), make sure you remember the following table or print the table and hang it next to your screen to win the next discussion with your fellow SEOs 🙂
There are three ways you can interact with the wandering robots and give them directives for crawling and instructions about indexing:
- The robots.txt file: this file gives the robots crawling directives, where are they allowed to crawl and which parts of the website or URLs they are not allowed to crawl.
- X-Robots-Tag HTTP header: this tag, added to the HTTP header is an equivalent of the robots meta tag. This can be implemented per URL but also on server level via the .htaccess file for example. Via this method, indexing can be controlled on a page-by-page level.
- The robots meta tag: this additional HTML tag gives instructions on a URL level.
- Search engine specific: via Google & Bing & Baidu Webmaster Tools and Yandex Webmaster you can additional input on the behaviour of their crawling and indexing systems. The disadvantage of using this way is that you have to setup all the instructions per search engine individually.
When a crawling bot visits a website, it first checks the robots.txt file, configuration in Webmaster Tools, next is the HTTP header and last is the robots meta tag in the HTML. The steps a search engine takes are:
- Crawling the website, wherever it is allowed to crawl within the domain
- Processing and indexing the pages it can find in their internal database
- Deciding on which pages are allowed to show up in the search engine result pages, filter pages with noindex tags for example.
- Repeat the process: if indexing instructions change, removing content from the live index
15:43 Update via John Mueller from Google: This image is wrong … It looks like a great idea though! Feedback from John:
- robots.txt: only blocks crawling, not indexing, doesn’t remove URLs form the search results
- x-robots-tag & robots meta-tag have same effects: can block indexing (but not crawling), can remove a URL from the search results
- Webmaster tools (at least from Google): can remove a URL / folder / site from the search results (but that doesn’t stop crawling & indexing)
Get’s you thinking about the order in which things take place. How can Google notice a noindex element without crawling an URL?
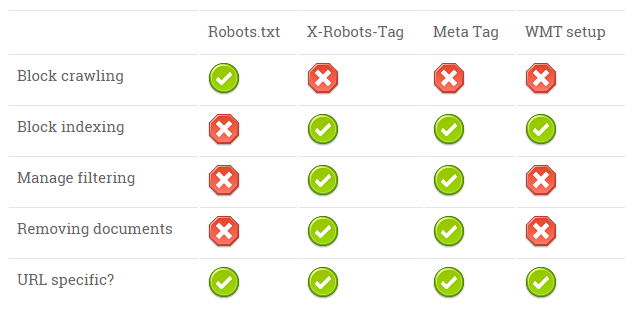
Search Robot Management Cheatsheet
| Robots.txt | X-Robots-Tag | Meta Tag | WMT setup | |
| Block crawling | ||||
| Block indexing | ||||
| Manage filtering | ||||
| Removing documents | ||||
| URL specific? |
Official sources by the search engines:
About specific configurations, have a look at the official documentation provided by the search engines:
– Google: Robots meta tag and X-Robots-Tag HTTP header specifications
– Google: Robots.txt Specifications
– Bing: Crawl Control
– Yandex: Using robots.txt
– Yandex: Using HTML tags
– Baidu: User manual: Robots related
Very helpful. Thank you for putting this together. I’ll probably reference this many times.
It is obvious that if you block Googlebot to access a URL disallowed in the robots.txt, they cannot notice a noindex directive.
Disallowing directories or pages in the robots.txt must only be your last choice.
But how about the situation in which the URL already was indexed and you want to deindex it? How about crawl budget, adding meta tags still require crawling effort, blocking in robots.txt limits this 🙂
A Cheatsheet, good Idea man. Thanx! How to include or not include the nofollow tag whould be helpfull cause many webmasters still don’t know how to handle and combine with noindex.