I’ve been creating a lot of (data driven) creative content lately and one of the things I like to do is gathering as much data as I can from public sources. I even have some cases it is costing to much time to create and run database queries and my personal build PHP scraper is faster so I just wanted to share some tools that could be helpful. Just a short disclaimer: use these tools on your own risk! Scraping websites could generate high numbers of pageviews and with that, using bandwidth from the website you are scraping.
Scraper is a simple data mining extension for Google Chrome™ that is useful for online research when you need to quickly analyze data in spreadsheet form.
You can select a specific data point, a price, a rating etc and then use your browser menu: click Scrape Similar and you will get multiple options to export or copy your data to Excel or Google Docs. This plugin is really basic but does the job it is build for: fast and easy screen scraping.
2. Simple PHP Scraper
PHP has a DOMXpath function. I’m not going to explain how this function works, but with the script below you can easily scrape a list of URLs. Since it is PHP, use a cronjob to hourly, daily or weekly scrape the desired data. If you are not used to creating Xpath references, use the Scraper for Chrome plugin by selecting the data point and see the Xpath reference directly.
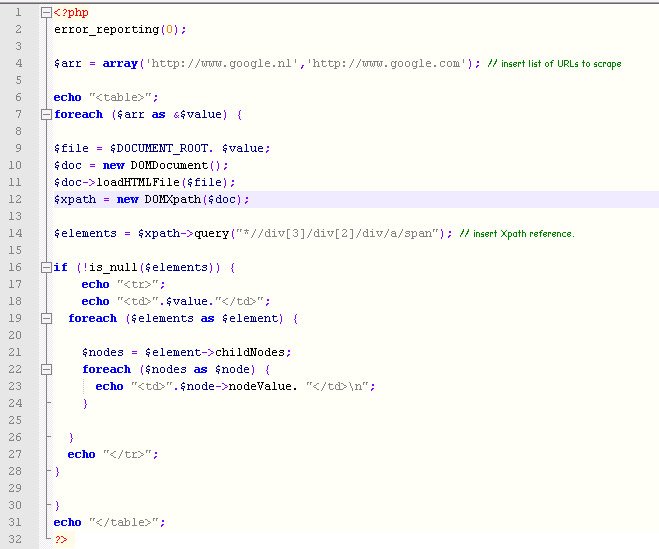
– Click here to download the example script.
3. Kimono Labs
Kimono has two easy ways to scrape specific URLs: just paste the URL into their website or use their bookmark. Once you have pointed out the data you need, you can set how often and when you want the data to be collected. The data is saved in their database. I like the facts that their learning curve is not that steep and it doesn’t look like you need a PHD in engineering to use their software. The disadvantage of this tool is the fact you can’t upload multiple URLs at once.
4. Import.io
Import.io is a browser based web scraping tool. By following their easy step-by-step plan you select the data you want to scrape and the tool does the rest. It is a more sophisticated tool compared to Kimono. I like it because of the fact it shows a clear overview of all the scrapers you have active and you can scrape multiple URLs at once.
5. Outwit Hub
I will start with the two biggest differences compared to the previous tool: it is a softwarepackage to use on your PC or laptop and to use its full potential it will cost you 75 USD. The free version can only scrape 100 rows of data. What I do like is the number of preprogrammed options to scrape which makes it easy to start and learn about web scraping.
6. ScraperWiki
This tool is really for people wanting to scrape on a massive scale. You can code your own scrapers (in PHP, Ruby & Python) and pricing is really cheap looking to what you can get: 29USD / month for 100 datasets. You are completely free in using libraries and timers. And if your programming skills are not good enough, they can help you out (paid service though). Compared to other tools, this is the most advanced tool that offers the basics of web scraping.
7. Fminer.com
This tool made it possible to finally scrape all the data inside Google Webmaster Tools since it can deal with JavaScript and AJAX interfaces. Read my extensive review on this page: Scraping Webmaster Tools with FMiner!
But on the end, building your individual project scrapers will always be more effective than using predefined scrapers. Am I missing any tools in this sum up of tools?
Comments
136 responses to “Seven tools for web scraping – To use for data journalism & creating insightful content”