
During my flight from Washington to London yesterday night, I was thinking about who I am. What makes me different from the other 200+ passengers? Thanks to Google’s additional Knowledge cards, Yandex Islands any many more. Because search engines added all kinds of additional data in their search engine result pages during the last years, we get more and more “quantified” and we are getting more conscious about who or what we are, especially on the web. The whole “From strings to things” concept is being visualized for the average person by companies like Google. Currently, Google shares more facts about me (I’m sure they know a lot more since I used their services since 2000), than the average number of facts my friends will remember about me. How can you not like science?
There is one remark I have to make, I gave this information directly to Google by creating a personal page on Freebase. Freebase was acquired by Google in 2010 for one simple reason: all the data in that knowledge graph, was already annotated and directly useable for research projects. There is one issue with this, currently all these freely accessible knowledge graphs, like Freebase, are maintained by humans. As Einstein said:
“Two things are infinite. The universe and human stupidity. …I’m not so sure about the universe”.
It’s not only that flaw, but think about how easy it is to game that system. Two weeks ago, there was some noise in the search marketing community, about Google making the next step with their knowledge graph. Knowledge Vault was introduced to the public, via an article about a paper that was going to be presented during the “Knowledge Discovery in Databases (KDD) conference” in New York. This is the original paper: Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion – http://bit.ly/knowledgevault
Not many people realize Google is constantly doing research, of which a fair bit is shared via scientific conferences around the globe, 12 months a year. This paper was presented by a junior researcher but Google employees have previously referenced to “Knowledge Vault” as a concept in more papers. Yahoo shared that they are busy with building a knowledge graph too, during the SemTechBiz Conference & Expo in late August.
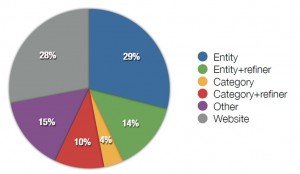
All these developments are not new at all, but during the past months, several well-known brands in the search & scientific environment have made big steps. Looking to the current state of web search, I tried to find adequate data but unfortunately I couldn’t find any research to the distribution of web search queries after 2011. In 2011, Lin et all shared the following data, which clearly shows entities are making up a large part of the queries. Especially if you consider website URLs as entity references too:
The semantic web is not something of the past two years. In 2001 Tim Berners Lee already shared his vision on the Web 2.0 and started a collaboration group, under the flag of W3C, named “The Semantic Web”:
The Semantic Web is a collaborative movement led by international standards body the World Wide Web Consortium(W3C). The standard promotes common data formats on the World Wide Web
And their goal is quite clear:
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries
So basically, in a oversimplified world, you need three things to accomplish that goal:
1. Data
2. A Mark-up language
3. URLs to share the data
As mentioned before, Freebase is just one of the databases, also referred to as knowledge graphs, that can be used as a source of data for anyone. Google is currently doing research on the (personally one of the most interesting) topics of automatic entity retrieval, linking and verification. By crawling the web, using natural language processing techniques, systems are able to detect relationships in corpora (large and structured set of texts) and extracting entities from the corpus of the web. Entity linking can be done via various ways, based on historical and current activity researchers can identify relations between concepts. The most interesting step is entity verification. The problem companies like Google need to tackle, is to get rid of the human factor in their databases and build an autonomous system.
If I create a page on Freebase, engineers can use that data as a starting point. Then it can check the quality of that data, by different methods of verification:
- Use a search engine. Does the data correlate with other sources in a search engine index. For Google this is an advantage since they have direct access to these sources.
- Ask people. In the papers about Knowledge Fault, they reference to another paper describing a system to conduct quizzes: Quizz: Targeted Crowdsourcing with a Billion (Potential) Users
- Get direct feedback from users. Google currently provides feedback buttons in most of their Knowledge graph cards in the SERPs.
- Use anchor texts as identifiers, again this is data Google has ready to use and their competitors don’t have.
- Implement user signals to determine data quality. If people always search for specific combinations of entities, big chance there will be a relationship. Bill Slawski wrote an excellent piece about that: How Google Decides What to Know in Knowledge Graph Results
So far this is focused at Google, but the beauty of a semantic web is that everyone, every computer, every piece of software is able to interact. To make that possible, you will need a general consensus of how that data is presented if being requested. In the previous session, Matthew Brown has shared a bit more insight about the current state of some of the mark-up languages: Rich Snippets – After the Fire. I expect JSON-LD is the best until date, for several reason so hopefully adoption will benefit from it.
Knowledge graphs nowadays
Most marketers are familiar with Freebase, because Google is directly involved and the links are not provided with a nofollow tag. To give you an idea of what is already developed you can find some of the lesser known databases which are freely accessible and could function as a resource for different purposes:
DBpedia – http://dbpedia.org/About
This community is crowd sourced and extracts all the information from Wikipedia and make this information available in a machine readable (so structured data J) way. You can download these datasets, or query the data via various APIs. The English version of the DBpedia knowledge base describes 4.58 million things, out of which 4.22 million are classified in a consistent ontology, including 1,445,000 persons, 735,000 places (including 478,000 populated places), 411,000 creative works (including 123,000 music albums, 87,000 films and 19,000 video games), 241,000 organizations (including 58,000 companies and 49,000 educational institutions), 251,000 species and 6,000 diseases.
GeoNames – http://www.geonames.org/
This is a database with geographical data, which is free to use. GeoNames is integrating geographical data such as names of places in various languages, elevation, population and others from various sources. It contains over 10 million geographical names and consists of over 9 million unique features whereof 2.8 million populated places and 5.5 million alternate names.
eagle-i – https://www.eagle-i.net/
This is a collaboration of universities, resulting in a free application to discover resources from research being done in the field of biomedical research. It was started by 9 academic institutions, mainly focusing on biomedical scientists. In the scientific world it is common to collect a lot of data, publish a paper about the research findings and not sharing the data. That means others have to repeat the data retrieval again, don’t share their findings in a structural way. The New York Stem Cell Foundation (NYSCF) Research Institute and eagle-I are collaborating to create transparency in stem cell research. Exchanging information is key in future research.
FishBase – http://www.fishbase.org/
Everything you want to know about fish! They had 50 million hits in May 14, 470.000 unique visitors. Not bad for just a database about fish J It is used by different professionals such as research scientists, fisheries managers, and zoologists. It is including information on taxonomy, geographical distribution, biometrics and morphology, behaviour and habitats, ecology and population dynamics as well as reproductive, metabolic and genetic data.
From a marketing perspective, these easy to access databases, can be used to enrich your marketing activities. To sum it up:
- Accessible via API
- Data is free to use
- Sharing data = link building
- Enrich your content & apps
DBpedia is having a service, DBpedia Spotlight which can be used to directly insert information in your website via an installation on your server. It can annotate your data on the fly, which can provided your users with additional information. If you mention brand names or persons, it is nice to provide the user with background information about that specific entity.
Google has developed an easy-to-use API for FreeBase. You can query all kinds of data points to enrich your current content or interlink pages based on topical relevance or connections and relationships between concepts and entities based on what users have inserted into FreeBase. Start with: Get Started with the Freebase API
The practical Semantic Web
The result of more than 15 years of building and thinking about the next version of the web, is still not very visible. Most marketers know the semantic web by the knowledge cards in Google, the yellow ratings in the SERPs because of structured data and that is it. Luckily there are more and more cases being shared and below you will find some interesting cases of the semantic web as it is meant to be:
Best Buy – Slides
Jay Myers shared some insights about his internal optimization by using semantic structuring of their data. They implemented systems to automate product linking, optimize long tail product pages and topical product recommendations. This resulted in increased conversions varying between 5 and 11 times. Check his presentation: Practical Applications of Semantic Web in Retail — Semtech 2014
BBC Wildlife finder – http://www.bbc.co.uk/nature/wildlife
On this website, BBC is making use of different database and combining them into a central point of information. To interlink all the information shared during programs and on all their separate websites, they have developed systems to make all their data available to developers and combine it with external sources. BBC Nature aggregates data from different sources, including Wikipedia, the WWF’s Wildfinder, the IUCN’s Red List of Threatened Species, the Zoological Society of London’s EDGE of Existence programme, and the Animal Diversity Web.
Skeletome
During the keynote of the “Semantic Big Data in Australia” conference, Jane Hunter from the University of Queensland (video) shared some interesting cases about how her team used semantic web technologies to support scientific projects. One of them is Skeletome: A community-driven knowledge curation platform for skeletal dysplasias, referred to as Dwarfism by most people. The term is an umbrella for a group of hundreds (!) of conditions affecting bone and cartilage growth.
With this platform, researchers can make things possible that wouldn’t be possible if they weren’t collaborating on a semantic way. Medical doctors share client cases (anonymously) on which others can reply and share their diagnosis. Every time data is added, calculations can be made and prediction of diagnosis get better.
What makes Skeletome unique:
- Extract / infer new relationships: Disease <-> phenotypes <-> genotypes
- Analysed diagnoses across patients and publications
- Measuring trust based on social metrics, expertise and past contributions.
Linked Open Drug Data
Another case in which researchers are limited by the lack of a comprehensive information repository. By combining all the available datasets, answering interesting scientific and business questions becomes more easy. Data sources range from medicinal chemistry results, over the impact of drugs on gene expression, to the outcomes of drugs in clinical trials.
Similar cases can be found on the W3C website: Semantic Web Case Studies and Use Cases
Some of the challenges the Semantic Web is facing:
- Create more cases outside the scholar community.
- Standardization of mark-up formats
- Develop platforms to ease adoption
Semantic Web Resources
I always get the questions after sessions like this, where I get all this information. I have to be honest, I’m following a lot of different sources to be sure I’m on top of the latest developments. I’ve divided them into beginners and more advanced sources.
Beginners resources:
- G+ community: Semantic Search marketing
- 30+ Semantic Web Introductions, References, Guides, and Tutorials
- A guide (PDF) to LinkedOpen Data
- Practical Semantic Web and Linked Data
Advanced resources:
- Follow the annual scientific events: ISWC, KDD, WSDM, SIGIR, WWW, KESW, ESWC, SWWS, JIST, SWIB, SEMANTiCS, IEEE -> download papers + workshops and also visit the website of previous years.
- Follow papers: http://scholar.google.com, & patents (filter by authors & topics) http://www.google.com/advanced_patent_search
Comments
3 responses to “The Semantic Web & Structured Data – #BrightonSEO”