Many technical (SEO) online marketers are familiar with the nice piece of software called Screaming Frog. Functionalities are varying from checking duplicate pages, titles and meta descriptions to investigating technical issues regarding HTTP header status, crazy redirect constructions etc. The program only costs you 99GBP a year, which is really cheap considering the fact that most SEO consultants will use it on a daily basis.
However, there is one big problem. Screaming Frog is a program that runs in Windows, locally. Which means the software depends on the boundaries of your PC or laptop hardware. During the process of crawling a specific website, Screaming Frog stores certain data points into your RAM memory. Depending on the size of your memory available, there is a restriction in the number of pages, files or URLs the program can handle. Everyone can easily try to detect the limits, by starting to crawl a website like Amazon.com or Ebay.com. Those websites have millions of unique pages and I can assure you, the average computer will not get that far into those websites. This will result in the following message:
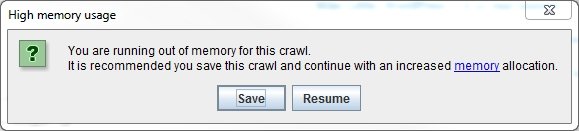
Another problem I have with Screaming Frog is that you can’t crawl multiple websites with one command. This is useful when you want to analyse link networks for example. Once you identified certain members within a blogging network, it saves you a lot of time when you can input the list with blogs and get all the external linked websites back.
How to deal with those huge websites?
As I am working for some bigger than average websites in terms of indexed pages and visitors / day, I had to find a solution for this problem. There are some commercial solutions for it, one of them is the UK based Deepcrawl. They had the same problem as I had and made a commercial solution for it. The problem I have with commercial solutions is that you are bound to the restrictions of the software package you are buying.
This made me think: “How can I build a scalable solution for crawling websites with more than 1.000.000 URLs?” There are many open source crawling systems available, of which only a few are really suitable for the job. Depending on the language you’re able to program yourself, you could take a look at the following options:
- PHPCrawl – PHP
- Sphider – PHP
- Crawler4j – Java
- How to write a multi-threaded crawler in Java
- Scrapy – Python
- Harvestman – Python
Disclaimer: be aware of the fact that you can be blocked by a server or bring down a website by crawling through it too aggressively.
Using PHPCrawl as the base of your Big Ass crawling software
Unfortunately I’m only able to code PHP and SQL so the best option for me to start with, was the PHPCrawl library. It actually is a really complete web crawling system which can be easily tweaked based on your needs. I know that solutions based on programming languages like Java or C++ are more suitable for doing fast crawling tasks, especially because of the fact that you can speed up the process of crawling by running multiple instances of the software and make use of multicore processors. PHPCrawl is able to run multiple instances from the command prompt, but not every server is suitable for that. You need to check the required specifications for that on their website.
So once you have installed this library on your local or external server, you need to setup a database to store the information. I think the easiest way to save your data is in a MySQL database. I’m not going to get into the details to much, because I expect people that want to work with such a crawler have enough programming skills to develop their on system (frontend and backend databases), based on their needs.
You can download a small PHP + MySQL example (ZIP file) which you can use to crawl a specific domain, or an array of domains, for all internal and outgoing links. The data is stored in a MySQL database. I think it this is a simple and clear example to start with.
For big sites, the system will need so time to get all the URLs. You can easily speed up the process by running multiple instances. For more information about the setup of PHPCrawl to complete processes faster, read the instructions on the website. If you run multiple instances to speed up the process, be aware of the fact that servers can block your IP based on the high number of requests per second you are doing. To avoid this, you could build in a proxy system so every request will go through a random IP address.
You do need to make sure you use database caching instead of using local memory, otherwise you will get the same issues as with Screaming Frog. RAM memory is limited, databases aren’t. PHPCrawl is able to cache data in a SQLite database. Just add a single line of code to your script: visit the webpage of PHPCrawl to read the instructions.
The basic implementation of PHPCrawl starts with a single domain and crawls every URL that it finds. You can also instruct the crawler to only crawl a specific domain. By using a simple loop, you can easily insert an array of domains so it can check and analyze specific networks.
If you have any questions regarding the setup of crawlers, don’t hesitate to reply to this blog post. Any help with data processing? Just e-mail me at noinfo@notprovided.eu. I also would like to know how you are dealing with crawling sites with more than one million pages, please share your experiences in the comments.
Comments
2 responses to “Big Ass SEO: is your site too voluminous to crawl with Screaming Frog?”