A lot of people have heard about structured data but not that many are fully familiar with the possibilities and tricks you should know. A lot of different terms are used to described the way websites can make use of the movement towards a semantic web, a movement which the web is under going to at the moment.
To clarify every aspect of this the subject “Structured Data” I will show some of the possibilities that the web is giving us nowadays. First thing to keep in mind is there are multiple ways of marking your data so other crawlers, algorithms and external websites can understand certain types of data. Most known are the following markup languages:
- Schema.org
- RDFa protocol
- Microformats
- Open Graph protocol
These languages all serve different purposes but on the end there is one main factor: make your content readable for crawlers in an efficient way. But first we have to go back in time, and have a look at W3C Semantic Web:
The Semantic Web is a collaborative movement led by international standards body the World Wide Web Consortium (W3C). The standard promotes common data formats on the World Wide Web
The goal of this movement is clear: convert the web and make sure that the web is structured based on entities instead of keywords. One of the targets is to create a network of linked open data, in which governments, companies and private organisations make use of similar markup languages so data can be shared easily.
From an online marketing perspective we have two fields in which we can benefit from the possibility of using structured data: both for SEO and Social media marketing purposes. Since the early days a lot of blogs have been discussing the possibilities but I wanted to know how many websites actually make use of these techniques. I setup some crawlers on Amazon EC2 instances which are easily scalable. Based on the Alexa top 1 million websites, I started a crawl which resulted in the following outcome:
– Crawled with an average rate of 360 URLs per second
– 68% (683.267 URLs) returned a 200 OK status
– During the crawling, 68.4 gigabyte of data was processed
– 27% of the domains visited, where redirected with some sort of 30X redirect
– 3% of the domains had DNS issues
I checked my dataset on the presence of 7 code snippets and this resulted in the following graph:

A commercial solution which is continuously crawling the web is Builtwith.com and their data is almost the same as mine. I find Builtwith.com somewhat expensive for just gathering some market intelligence data, the costs of crawling it with Amazon services are just 12,36USD if you’re doing it right 🙂 Based on this data, I think there are still a lot of opportunities considering the fact that since the biggest websites haven’t integrated it on a large scale, the playing field is still quite open. So let’s get back to the data markup languages:
Microformats originates from early 2003, when webmasters started to markup some links with the tag rel=”friend”. In 2004 during eTech, Tantek hosted a presentation titled “Real World Semantics”. Please visit his slides to get an idea about how they were discussing the semantic web. Just after five years, Google started accepting some of the microformat markup, specifically hCard, hReview and hProduct. RDFa was first proposed in 2004 and since 2011 RDFa 1.1. is recommend to be used within HTML4 and HTML5 coding.
The essence of RDFa is to provide a set of attributes that can be used to carry metadata in an XML language (hence the ‘a’ in RDFa).
Based on this, Google started parsing this additional markup internationally in April 2010.
Because of all the different markup language being develop, Schema.org was initiated and launched by three major search engine providers in June 2011: Google, Yahoo and Microsoft were involved. This also makes this markup language a preferred way of marking up your language if you want to be sure search engine crawlers can understand your content.
SEO and structured data
During the past three years a lot has been written about implementing structured data to get Rich Snippets within the search engine result pages your website is included. Most websites have used the Review snippets to include the yellow stars, which will guarantee a higher click-through rate if you’re one of the only URLs with this extended SERP snippet. Within Google the following rich snippets are possible:
All these snippets can be used separately based on the page content and snippet relevancy, but some snippets can be combined. Using a breadcrumb together with product data, or aggregated ratings together with offer details:

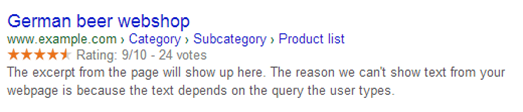
Some URLs you should add to your bookmarks once you start optimizing your rich snippets:
- Schema Creator by Raven
- Schema.org Generator
- Rich Snippets Testing Tool Bookmarklet
- Structured data guide by SEOGadget
In the early days it was as easy as just including the markup code within your HTML, Google robot finding your code and waiting to be indexed. A lot of websites have been using this possibility in the wrong way. Including review snippets when there are no reviews on your website. Using Recipe snippets to include your product images within the SERPs. At a certain point we had a top 10 in which 9 URLs where having some sort of rich snippet attached. That doesn’t make sense and the attribution for the user was not useful anymore. Google started accepting rich snippets because websites would be able to be different to each other within the SERPs but if everyone is having the same attributions, there is no added value at all.
During the past 6-12 months, Google cleaned up the SERPs from a rich snippets point of view. They have been more picky to which sites deserve specific attributions. Unfortunately I haven’t found any logic in why some websites do have certain snippets and why others haven’t. You would think Google would look to the authority of specific domains or pages. I still have some websites that have no authority at all, that have review or offer snippets. The only pattern I can detect is that niches which have a high amount of search volume, are “cleaner” compared to the lower volume niches.
How to implement? Make sure:
- You have specific data points available
- SE’s accept specific markup language
- SE’s accept certain snippets
- Information within the SERPs is correct
- Implement code and check with the SE’s:
Review snippet recommendations
First thing I do once I start an optimisation project is trying to get rich snippets implemented. The increase in traffic, just by implementing some lines of HTML is a nobrainer for me. For e-commerce websites it’s easy: implement product reviews. For other websites I would always ask myself the question: is there something to get reviewed on my website? Reviews are not only good for the rich snippet purpose, but also conversion wise a must have on your website.
Aspects to take into account
If you have implement prices and offer markup, be aware there is a delay in crawling your code, indexing & processing by algorithms and pushing it to the live indices of search engines. Only if you are sure that your prices will not change on short term, include them on product level. A safe way, and in most cases also targeting higher volume keywords, is implement price ranges on category level. Another pitfall is the fact that the Google Testing tool only shows errors based on missing elements, not on wrong coding! So make sure you nest all your markup data in the correct way. Once you have uploaded your new HTML templates, you can monitor the way Google is picking up your structured data within your Webmaster Tools dashboard and can zoom in on page level errors.
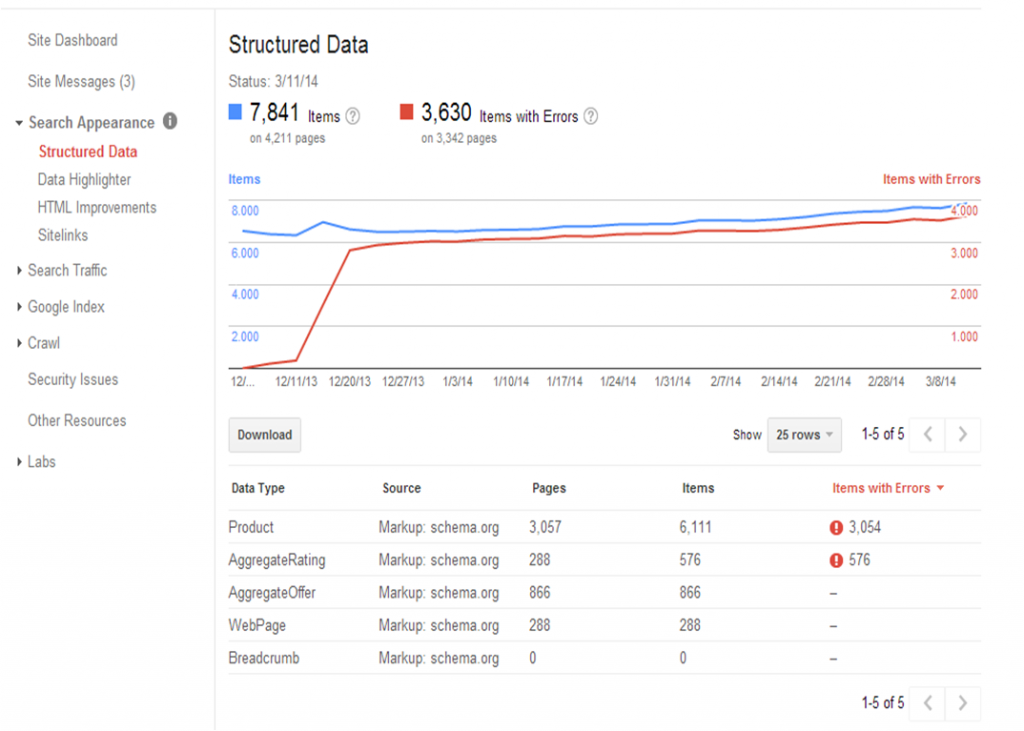
If you’re not able to change your HTML, Google launched a Data Highlighter tool. Within this tool you can select the data you would like to be seen as marked up data and Google can help you indicate the different data points without having to change your HTML. I’ve tested this tool numerous times, but I’m not really good results with it. So I recommend just to stalk your web developer or learn Schema.org so you can change your website yourself without the help of Google. Another thing you have to keep in mind is that this tool is only for Google, so you’re keeping the other search engines out of the loop.
The risks of playing with rich snippets
Google has told us that there is something like a rich snippet penalty. Once you have been detected as a “rich snippet spammer” they can tag your site and you will never be able to get rich snippets again, for that specific domain. Until 9 months ago it was still possible that if you had been caught when using Schema markup, you could just change it to RDFa and Google would include your snippets again. I haven’t been able to perform such a trick during the last couple of weeks so I think Google tackled this tactic 🙂
A discussion I’m having with fellow nline marketeers is about the fact that you’re making it even more easy for external parties to scrape and use your data. Product data can be used for comparison websites or within Google’s knowledge graph extensions. We have seen Google launching their own products within verticals like Flights, Insurances and housing. If you are thinking that way, be sure you fully understand the capabilities of Google at this moment and within the future. They already have all your data, so if they want to use, they will.
Structured data for social networks
Let’s go back to the use of structured data for social networks. One of the first social networks that allowed marking up data and making it more easy to show specific data within their network was Facebook. They developed the OpenGraph protocol.
“The Open Graph protocol enables any web page to become a rich object in a social graph. For instance, this is used on Facebook to allow any web page to have the same functionality as any other object on Facebook.”
More detailed information about all the possibilities can be found at: OGP.me which shows multiple integration examples for different kinds of content. Once you have included open graph tags in your HTML, make sure you test them via Facebook’s Debugger tool. Once you have posted or tested an URL by liking or sharing it, Facebook is caching the information. I’ve seen a lot of complaints about Facebook showing the wrong images next to shared URLs, but that is often because the images changed between the first time it was posted and the final blogpost for example. Make sure to use the Debugger once every open graph tag is correctly filled. By using the Debugger, Facebook will empty the cache and will add the latest information to their database.
Next is Twitter, which created the opportunity to enrich tweets with their so-called Twitter Cards. By implementing specific tags, based on the OpenGraph protocol, you can implement pictures, descriptions and even videos within Tweets. Have a look at their extensive documentation to get an idea which tags you have to implement within your HTML. After implementing you have to validate and verify the Twitter Cards you would like to use. In the early days this could take two weeks but last time I tried (last week) it was almost immediately checked. I think Twitter has automated this and is just asking to verify because they want to be sure they can filter out spam more easy once they know which domains and accounts are using Twitter Cards.
To make it easy for you if you use WordPress, install the Yoast SEO plugin because this plugin has the ability to include the Facebook and Twitter OpenGraph tags easily and are customizable. Google Plus is preferring Schema.org markup, but can also handle the OpenGraph protocol.
This is what they state in their documentation:
• Schema.org microdata (recommended)
• Open Graph protocol
• Title + metadescription element
• Best guess from page content
You can use the rich snippet testing tool to check whether your implementation is done in the right way. I can definitely say that making use of these possibilities will create better results for your social media activities.
Comments
3 responses to “From structured data to rich snippets and social media optimisation”